Gateway とは
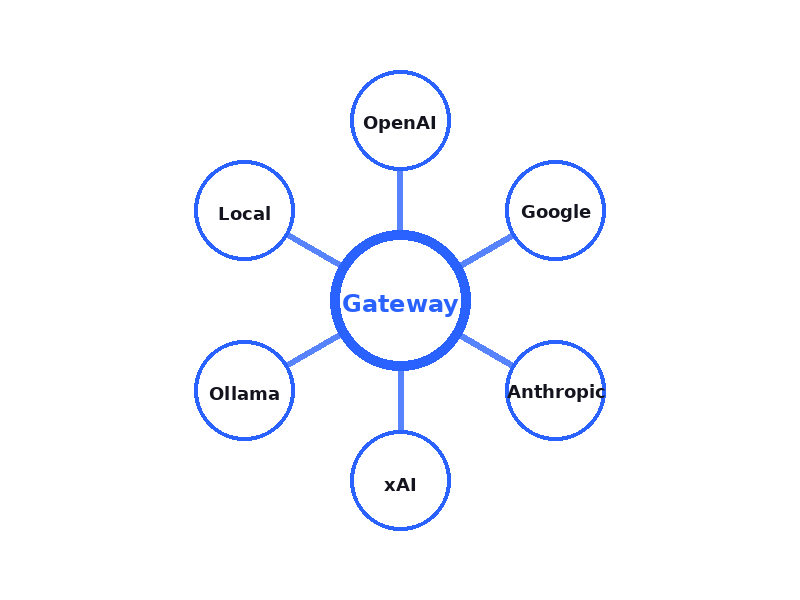
Gatewayは、OpenAI・Anthropic・Google・xAI・OpenRouter・llama.cppの7つのプロバイダーを1つのAPIで操作できるLLMプロキシサーバーです。
OpenAI Responses API形式とAnthropic Messages API形式の2種類のAPIフォーマットに対応し、リクエストのproviderパラメータを変えるだけで、クラウドサービスもローカルモデルも同じコードから利用できます。
Unified API
OpenAI Responses APIとAnthropic Messages APIの2形式に対応。providerパラメータを変えるだけで全プロバイダーを操作可能。

High Performance
Rust製の高速プロキシ。非同期処理とGPUアクセラレーションで高スループットを実現。

Local Execution
llama.cppを統合し、GGUFモデルをローカルで実行。データを外部に送信せずプライバシーを確保。HuggingFaceからのモデルダウンロードにも対応。
Gatewayが解決する課題
従来の問題
-
プロバイダーごとに異なるAPI
OpenAI、Anthropic、Googleそれぞれで実装が必要 -
モデル切り替えに時間がかかる
コード修正、テスト、デプロイのサイクルが必要 -
ベンダーロックイン
特定のプロバイダーに依存してしまう -
ローカルモデルの統合が困難
llama.cppなどのローカル実行は別途実装が必要
Gatewayの解決策
-
統一されたAPI仕様
OpenAI Responses APIとAnthropic Messages APIの2形式で全プロバイダーにアクセス -
パラメータ1つで即座に切り替え
リクエストのprovider/modelパラメータを変更するだけ。APIキーはリクエストごとの上書きも可能 -
プロバイダー独立
ツール定義、構造化出力、ストリーミングなど主要機能が全プロバイダー共通で動作 -
llama.cpp完全統合
GPU加速、Vision、Reasoning、Embeddings、Rerankまでローカルでサポート。HuggingFaceから直接モデルダウンロード可能
実装済みの機能
以下はすべて実装され、本番環境で使用可能です
7プロバイダー対応
Live
OpenAI、Anthropic、Google、xAI、OpenRouter、MLXの各クラウドAPIに加え、llama.cppによるローカル推論をサポート。リクエストのproviderフィールドで切り替え可能。

GPUアクセラレーション
Live
CUDA(NVIDIA)およびMetal(Apple Silicon)によるGPU推論。GATEWAY_GPU_LAYERSで層数を制御(-1=全層GPU、auto=自動判定、0=CPUのみ)。Flash Attention・マルチGPUにも対応。
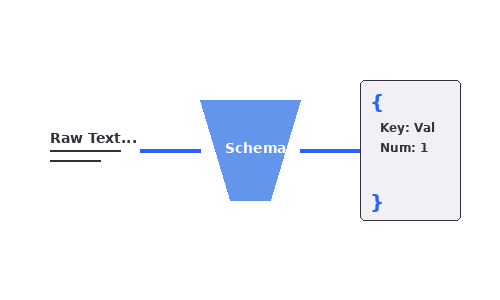
構造化出力(Structured Output)
Live
response_formatにJSON Schemaを指定することで、LLMの出力をサーバー側で検証。ローカルモデルではstrict・prompt・autoの3つの制約モードから選択可能。
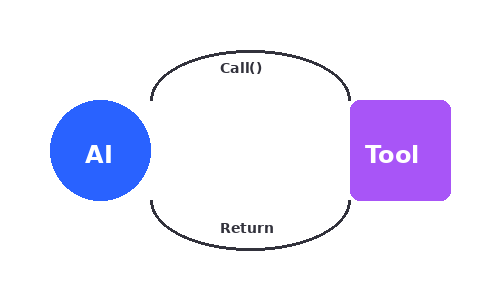
Tool Use(Function Calling)
Live
JSON Schema形式のツール定義を全プロバイダー共通でサポート。tool_choiceでauto/required/noneを指定可能。ローカルモデルではtool_strictによるJSON検証やtool_retryによる自動リトライにも対応。
マルチモーダル(Vision)
画像を含むリクエストをVision対応モデルで処理。ローカルモデルではmmproj(マルチモーダル投影ファイル)を自動検出し、gateway_options.mmprojで明示指定も可能。

ストリーミング & WebSocket
"stream": trueでSSE(Server-Sent Events)によるトークンごとのストリーミング配信。/v1/realtimeエンドポイントではOpenAI Realtime API互換のWebSocket双方向通信にも対応。

リクエストログ & 管理画面
全リクエストのプロバイダー、モデル、トークン数、レイテンシ、エラーを自動記録。/adminダッシュボードで統計を確認でき、/admin/logsからJSON形式でログを取得可能。

モデルキャッシュ & 自動メモリ管理
ローカルモデルを弱参照キャッシュで保持し、再利用時のロード時間を短縮。/v1/service/auto-unloadで一定時間アイドル状態のモデルを自動解放するメモリ管理が可能(デフォルト10分)。
Reasoning / Thinking モード
Live
LLMの推論過程を出力に含めるThinkingモードをサポート。gateway_options.reasoning_formatで形式を選択(auto/think_tags/analysis_final/off)。Anthropic APIのthinkingパラメータにも対応。
Embeddings & Rerank
Live
/v1/embeddingsでテキスト埋め込みベクトルを生成、/v1/rerankでドキュメントの関連度スコアリングを実行。ローカルモデルでも利用可能で、RAGパイプラインの構築に対応。
モデル管理(Pull / Load / Unload)
Live
/v1/local/models/pullでHuggingFaceからGGUFモデルをダウンロード、/v1/local/models/loadで事前ロード(GPU層数・コンテキストサイズ指定可能)、/v1/local/models/unloadで解放。ダウンロード状況の確認やキャンセルにも対応。
Gatewayを使うメリット
コスト最適化の柔軟性
Gateway自体は自動コスト最適化機能を持ちませんが、プロバイダー切り替えが容易なため、手動でコスト最適化戦略を実装できます:
- シンプルなタスク → llama.cppでローカル実行(APIコスト $0)
- 標準的なタスク → GPT-4o-mini($0.15/1M tokens)
- 高度な推論 → Claude Opus 4($15/1M tokens)
アプリケーション側でタスクの種類を判断し、適切なモデルを選択することで、大幅なコスト削減が可能です。
柔軟な切り替え
プロバイダーの障害やメンテナンス時に、手動で別のプロバイダーに即座に切り替え可能。自動フォールバックは未実装ですが、リクエストパラメータを変更するだけで切り替えできます。
実験の高速化
複数モデルの性能比較が容易。providerとmodelパラメータを変えるだけで、GPT-4o、Claude、Gemini、ローカルモデルを試せます。コードの再デプロイは不要です。
プライバシーとセキュリティ
機密データを扱うタスクはllama.cppでローカル実行。データが外部に送信されません。一般的なタスクはクラウドAPIで高速処理。
仕組み
アプリケーション
Gatewayに
1つのAPIコール
Gateway
指定されたプロバイダーに
ルーティング
任意のLLM
OpenAI, Claude,
Gemini, Grok, llama.cpp
コード例:モデル切り替え
API仕様・リファレンス
2種類のAPIフォーマットに対応し、統一されたパラメータで全プロバイダーを操作できます
対応APIフォーマット
Gatewayは以下の2つのAPIフォーマットをネイティブにサポートしています。どちらもすべてのプロバイダーに対して利用可能です。
| POST /v1/responses |
OpenAI Responses API互換input配列でメッセージを送信し、output配列でレスポンスを取得。ストリーミング時はresponse.output_text.delta等のイベントで配信。
|
| POST /v1/messages |
Anthropic Messages API互換messages配列でメッセージを送信し、content配列でレスポンスを取得。ストリーミング時はcontent_block_delta等のSSEイベントで配信。
|
全エンドポイント一覧
| 推論 | |
| POST /v1/responses | LLM推論(OpenAI Responses API互換) |
| POST /v1/messages | LLM推論(Anthropic Messages API互換) |
| POST /v1/embeddings | テキスト埋め込みベクトル生成 |
| POST /v1/rerank | ドキュメントの関連度スコアリング・並べ替え |
| POST /v1/messages/count_tokens | リクエストのトークン数カウント |
| GET /v1/models | 利用可能なモデル一覧 |
| GET /v1/realtime | WebSocket Realtime API(OpenAI互換) |
| ローカルモデル管理 | |
| GET /v1/local/models | ロード済みモデルの状態一覧 |
| GET /v1/local/models/available | ディスク上のGGUFモデルを検出 |
| POST /v1/local/models/load | モデル事前ロード(GPU層数・Flash Attention等を指定可) |
| POST /v1/local/models/unload | ロード済みモデルの解放 |
| POST /v1/local/models/pull | HuggingFaceからGGUFモデルをダウンロード |
| GET /v1/local/models/inspect/:model | モデル定義(ルール設定)の確認 |
| GET /v1/local/models/show/:model | GGUFファイルのメタデータ表示 |
| サービス管理 | |
| GET /health | ヘルスチェック |
| GET /v1/service/status | 稼働状況(起動時間、アクティブリクエスト数、GPU情報) |
| GET /v1/service/metrics | CPU・メモリ・GPU使用率メトリクス |
| GET/POST /v1/service/auto-unload | アイドルモデルの自動解放設定(取得・更新) |
| POST /v1/service/stop | 実行中の推論ジョブの中断要求 |
| POST /v1/service/shutdown | グレースフルシャットダウン(遅延指定可能) |
| 管理画面 | |
| GET /admin | 管理ダッシュボード(リクエスト履歴・トークン数・レイテンシ表示) |
| GET /admin/logs | リクエストログのJSON取得 |
共通リクエストパラメータ
すべてのプロバイダーに共通で使用できるパラメータです。providerとmodelを変更するだけでプロバイダーを切り替えられます。
gateway_options(ローカルモデル詳細設定)
ローカルモデル(llama.cpp)利用時に、リクエスト単位で推論の動作を調整できるパラメータです。
| パラメータ | 説明 |
|---|---|
| reasoning_format | 推論過程の出力形式。auto / think_tags / analysis_final / off |
| thinking | Thinkingモードの有効/無効。auto / on / off |
| tool_strict | Tool呼び出し時のJSON出力を厳密に検証 |
| tool_retry | Tool呼び出し失敗時の自動リトライ回数(最大3) |
| context_size | コンテキストウィンドウサイズの指定 |
| threads | 推論スレッド数 |
| seed | 乱数シード(出力の再現性確保) |
| chat_template | カスタムチャットテンプレートの指定 |
| mmproj | マルチモーダル投影ファイルパス(Visionモデル用) |
| repeat_penalty | 繰り返しペナルティ係数 |
CLIツール(gatewaycmd)
コマンドラインからGatewayの管理操作を実行できます。接続先はGATEWAY_HOST/GATEWAY_PORT環境変数(サーバと共通)または--base-urlフラグで変更可能です。
環境変数設定
始め方
環境変数を設定
使用するプロバイダーのAPIキーを設定します。
Gatewayを起動
1コマンドで起動します。
APIリクエストを送信
統一APIで任意のプロバイダーを使用できます。
次のステップ
gatewaycmd pullでHuggingFaceからモデルをダウンロードし、provider: "local"で無料推論を開始
/adminでリクエスト履歴・トークン使用量・レイテンシを確認
gatewaycmdでモデルの事前ロード、自動メモリ解放設定、ステータス監視を実行
タスクの種類に応じてproviderとmodelを使い分け、コストと品質のバランスを調整
現在の制限と今後の計画
透明性を重視し、現状の制限を明示します
自動フォールバック機能
プロバイダー障害時の自動切り替え機能は未実装です。現在は手動でプロバイダーを切り替える必要があります。
スマートルーティング
タスク内容に応じた自動モデル選択機能は未実装です。アプリケーション側でロジックを実装する必要があります。
コスト分析ダッシュボード
トークン使用量は記録されますが、コスト計算や最適化提案機能は未実装です。手動で分析する必要があります。
MLXネイティブ統合
macOS/Apple Silicon環境でMLXを直接利用可能です(ビルド時に--features mlxフラグが必要)。provider: "mlx"でMLXネイティブ推論を実行できます。